「コンピュータによる自動的」X (Twitter) スパム判定の解除方法 — 一般ユーザーから開発者まで

X (旧Twitter) を使っていて、次のような画面に突然なったことはありませんか?「このリクエストは、コンピュータによる自動的なものと判断されました。アカウントをスパムやその他の迷惑行為から保護するために、現在この操作は実行できません。しばらくしてからやりなおしてください。」これは X の 自動化検出 (behavioral fingerprinting) システム があなたのアカウントの行動パターンを bot 候補と判断した時に出る保護機能で、実際に自動化ツールを使っていなくても特定の操作パターンが trigger になります。
この記事は 2 種類の読者 に向けた完全ガイドです。(1) 一般ユーザー(自動化していないのに突然出た): 解除手順 5 ステップ(電話番号認証 → パスワード変更 → 異議申し立てフォーム → 行動パターン見直し → 時間を置く)、それぞれの効果と所要時間。(2) API 開発者(スクレイパー/bot が突然動かなくなった): HTTP 226/429/403 の正確な区別、なぜ proxy 旋転は 2026 年現在通用しないか、そして twitterapi.io への構造的移行という選択肢。
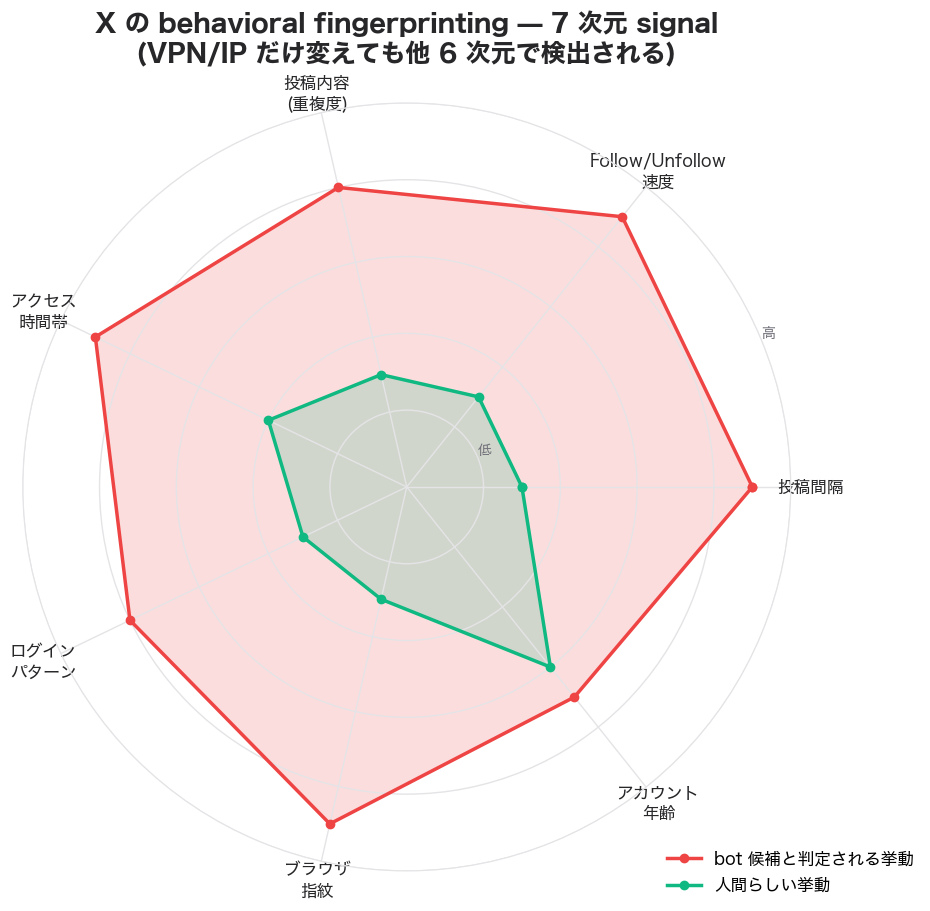
JA SERP の競合記事(camtsuku / note / chiebukuro 等)に頻出する 2 つの誤解 を最初に潰します。(a) 「VPN を変えれば解除される」は通用しません — X は 2023 年以降 IP-only 判定から behavioral fingerprinting(TLS 指紋・header の順序・cookie 履歴・タイミング・アクセスパターン・ブラウザ指紋・アカウント年齢の 7 次元)にシフトしました。IP だけ変えても他の 6 次元が同じなら検出されます。(b) HTTP 226 はステータスコードではありません — RFC 3229 で定義される "IM Used" は delta encoding 用です。X API の 226 は HTTP 403 Forbidden のレスポンス body 内の error code。混同するとコード側の error handling が機能しません。
「コンピュータによる自動的」エラーとは何か
X が出すこのエラーは、X が「あなたのアカウントの行動パターンが bot に似ている」と判断した時 に出る保護機能です。実際にあなたが自動化ツールを使っていなくても、特定の操作パターンが trigger になります。
エラーメッセージの正確な文字列 (X UI で表示されるもの):
> このリクエストは、コンピュータによる自動的なものと判断されました。アカウントをスパムやその他の迷惑行為から保護するために、現在この操作は実行できません。しばらくしてからやりなおしてください。
API レスポンスでの表示形式:
```json
HTTP/1.1 403 Forbidden
Content-Type: application/json
{"errors":[{"code":226,"message":"This request looks like it might be automated. To protect our users from spam and other malicious activity, we can't complete this action right now."}]}
```
重要な区別: 多くの古い記事や JA SERP 競合は "VPN を変えれば解除される" と主張していますが、2026 年の X は IP だけで判断していません。ログイン時間、投稿間隔、操作対象、ブラウザ指紋、アカウント年齢など、複合的な behavioral fingerprinting を使用しているため、IP 変更だけでは多くの場合解除されません。実際に効く対策は Section 2(一般ユーザー向け 5 ステップ)と Section 4(開発者向け 3 アプローチ)を参照してください。
このページは大きく 2 部構成です。前半 (Section 2-3) は一般ユーザー向けの即時解除手順と仕組みの解説。後半 (Section 4-5) は API 開発者向けの 226/429/403 区別と twitterapi.io への構造的迂回。あなたの状況に応じて該当部分を参照してください。
即時の解除手順 — 一般ユーザー向け 5 つのステップ
Step 1 — 電話番号認証 (最も効果的)
X の設定 → アカウント → 電話番号 で電話番号を未登録の場合、ここで登録すると 多くのケースで即時解除 されます。JA users の多くは Twitter 時代から電話を未登録のまま で、これが trigger になっています。X は "電話番号バインドされたアカウント = 本物の人間の可能性が高い" と判断するため、認証完了直後にスパム判定が解除されることが頻繁にあります。所要時間 ~5 分。
Step 2 — パスワード変更
アカウントの safety フラグをクリアするための signal です。X 設定 → アカウント → パスワード変更 → 強いパスワード(英数記号混合 12 文字以上)に変更します。これは「セキュリティ問題でロックされている疑い」の場合に効きます。所要時間 ~3 分。注意:複数回連続でパスワード変更を行うと、逆にロックが深まる場合があります — 1 回だけ実行してください。
Step 3 — 異議申し立てフォーム
Step 1-2 で解除されない場合の正式な申し立てルート。X の help.x.com には 2 つの異なる form があります:
- ロックされたアカウント専用フォーム: [https://help.x.com/en/forms/account-restoration/locked](https://help.x.com/en/forms/account-restoration/locked) — 該当アカウントにログイン状態が必要(automated 判定でロックされた場合の最短ルート)
- 一般異議申し立てフォーム: [https://help.x.com/en/forms/account-access/appeals](https://help.x.com/en/forms/account-access/appeals) — 72 時間以上経っても解除されない場合の正式 appeal
通常 24-48 時間 で返信が来ます。help.x.com のリンクは EN ですが、X のヘルプは browser locale で auto-redirect され、実際は JA で表示されます。
Step 4 — 行動パターンの見直し (再発防止 + ロック深刻化の阻止)
解除されても再発しないよう、以下のパターンを避けます:
- 短時間(1 分以内)に複数 follow / unfollow を繰り返さない
- 同じ文字列をコピペで連続投稿しない(同 URL の連投、同じハッシュタグの大量使用も含む)
- 自動投稿ツール (Buffer / Hootsuite 等) を使う場合は 1 分以上の投稿間隔 を設定
- 新規アカウント直後 30 日以内は急激な活動量増加を避ける
Step 5 — 時間を置く
上記すべてやって解除されない場合: 24 時間 待つ → 多くは自動解除されます。72 時間 経っても解除されない場合は永続ロックの可能性 → Step 3 の異議申し立てフォーム必須。
❌ やってはいけないこと:
- VPN を頻繁に切り替える — 逆に怪しまれます。X は IP 変更パターン自体を signal として使います
- 別のブラウザで何度も login を試す — 複数失敗ログイン試行は automation 検出を強めます
- 古い記事に書いてある「ブラウザ指紋を変える」拡張機能の使用 — Stylish / User-Agent Switcher 系は逆効果
- 「ロック解除サービス」に credentials を渡す — 多くはスキャム、永続停止のリスク + アカウント乗っ取りリスク
なぜ X はこの判断をするのか — behavioral fingerprinting の仕組み
2023 年以前の Twitter は IP アドレスをかなり重視 していました。しかし買収以降の X は behavioral fingerprinting に大きくシフトしています。具体的に X が見ている 7 次元の signal:
重要(目安として、確定数値ではない): 上記の閾値は X が公式に公開していません。JA dev community の観察 + 第三者報告に基づく 目安 で、X が内部仕様を変更する可能性があります。完全な閾値ではない ので、これらを満たさなくても他の signal で trigger される可能性があります。
つまり、自動化ツールを使わなくても「ロボットっぽい行動」をすれば trigger されます。例えば、特定のテーマで集中的に発信していたら、ある日突然このエラーが出る場合があります。逆に、自動化ツールを使っていても、十分に「人間らしい」変動を入れていれば trigger されないこともあります。
"False positives are accepted." by X — X は誤検知(本物のユーザーがロックされる)を コストとして受け入れている と公式に明言しています。spam / automation 対策の優先順位を上げた結果、一定数のユーザーが "自動化と判断" されて引っかかります。これは plat side の trade-off で、私たちユーザー側からは「正しく振る舞っているのに引っかかった」という体験になります。
開発者の場合 — API エラー HTTP 226 / 429 / 403 の区別
X API 経由でアプリを動かしている時に同じような制限が出ることがありますが、HTTP ステータスコードと body 内の error code で原因が大きく違います。古い記事はこれを混在させて議論するため、対処方針が間違いがちです。
正確な区別表:
重要な誤解の訂正(JA dev community で頻発): HTTP 226 は HTTP status code ではありません。RFC 3229 で定義される HTTP 226 "IM Used" は delta encoding 用で、spam/bot detection とは無関係。X API における 226 は HTTP 403 のレスポンス body 内の error code です。コード側の error handling では、HTTP status と body code を 別々にログ + 別々に分岐 する必要があります。
HTTP 403 + body code 226 が一番厄介 — これは API key の問題ではなく、紐づいているアカウント自体が "bot 候補" とマークされていることを意味します。この場合は本ページ Section 2 の解除手順を一般ユーザーと同じく実行する必要があります。新しい API key を発行してもダメ、新規アプリ登録してもダメ — アカウントレベルの flag をクリアしなければ何も動きません。
HTTP 429 と 403 の使い分けは Day 3 ページ参照: より詳細な 15 分レート制限と月間 2M cap の話は [/ja/blog/x-api-seigen](/ja/blog/x-api-seigen) で解説しています。本ページは spam/automation 判定 (HTTP 403 + code 226) に焦点を当てています。
proxy 旋転 / header spoofing が効かない理由(2026 年版):
JA 古い記事の多くは「レジデンシャルプロキシで IP を変えれば突破できる」「User-Agent を変えればバレない」と主張しますが、X の behavioral fingerprinting は IP / UA より深い signal を見ています:
- プロキシ: 検出は IP-based から fingerprint-based に進化済み。新しい IP でもクッキー履歴・タイミング・TLS 指紋が同じであれば、X はそれを「同じクライアントが IP を変えた」と判定します
- Header & User-Agent spoofing: ブラウザは UA 以外にも数十の signal を leak しています — TLS フィンガープリント、header の順序、JS 実行環境、画面サイズ、タイムゾーン。1 つや 2 つを matching するのは簡単ですが、本物のセッション全体で一貫して合わせるのは、結局あなたが構築したいデータパイプライン以上に難しい
- リクエストレートを下げる: 1 秒に 1 リクエスト → 1 分に 1 リクエストへ落としても、純粋なレートベース検出には効きますが、behavioral fingerprinting には block 発動までが少し遅くなるだけ
根本対策は 2 つだけ: (a) API 側の使い方を見直す(認証経由・公式ルートで)、(b) 構造的に第三者 API (twitterapi.io) に切り替える。Section 5 で詳述します。

twitterapi.io で X API の制限から構造的に解放される
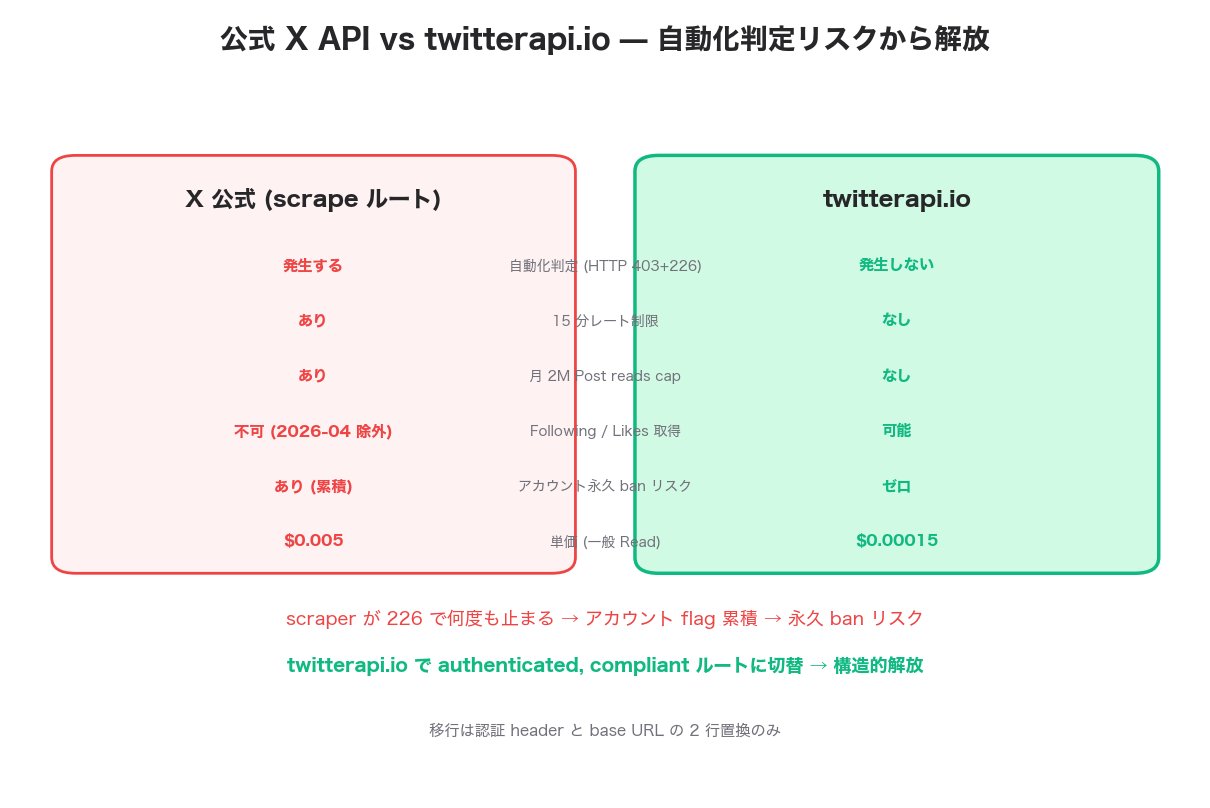
twitterapi.io は X 公式 API と互換性を持ちつつ、15 分レート制限・月間キャップ・self-serve 除外・spam/bot 判定の 4 つの問題から開放された第三者 API です。 "問題の構造" 自体を取り去ることが目的。
主な特徴:
- 15 分レート制限なし — リクエストを 1 秒で 10,000 投げても問題なし
- 月 2M Post reads cap なし — 月 5M、月 10M も対応可能
- Following / Likes / Quote-Posts も取得可能 — 公式 self-serve から除外された endpoint も使える
- "自動化と判断" される心配なし — twitterapi.io は X 公式 API を authenticated, compliant な経路で読むため、scraper として block されません
- 月額固定費ゼロ — 実使用分のみ
- 1 リクエスト $0.00015 — 公式一般 read の 約 1/33(約 ¥0.024)
- X 公式 API と同じ endpoint 設計 — 移行コスト最小
- 日本のクレジットカード・請求書対応、消費税対応の領収書発行
移行は2 行の置換: 認証 header を Bearer Token から X-API-Key に、endpoint base URL を api.x.com/2/ から api.twitterapi.io/twitter/ に。それだけで /twitter/user/info、/twitter/user/last_tweets、/twitter/tweet/advanced_search 等の互換 endpoint が使えます。
特に 226 エラーで悩んでいる開発者向けの推奨パス: spam/automation 判定で何度も block されている場合、その都度 X 側で解除手順を踏むのは 持続不可能 です。アカウント flag は累積する傾向があり、何度も誤検知されると永久 ban のリスクが上がります。早期に twitterapi.io に migration して、X 公式アカウントは "スクレイピング用" としてではなく "普通のユーザーアカウント" として保護する のが現実的。
(CTA: [twitterapi.io 料金詳細はこちら →](/ja/blog/x-api-ryokin) + [X API 制限の完全ガイド →](/ja/blog/x-api-seigen) + [アカウント作成 (無料 + $10 voucher 同等) →](/sign-up) + [X API 互換 endpoint ドキュメント →](https://docs.twitterapi.io))
実装例: Python migration コード — 226 を返さない API へ
公式 X API から twitterapi.io に切り替える最小限のコード例。スクレイパーが 226 で何度も止まっている場合、この置換だけで behavioral fingerprinting の影響から脱出できます。
import os
import requests
API_KEY = os.environ["TWITTERAPI_IO_KEY"]
# === 移行前 (公式 X API): 226 で何度も止まっていたコード ===
# x_headers = {"Authorization": f"Bearer {X_BEARER_TOKEN}"}
#
# def fetch_user_timeline_official(username):
# # ある日突然 403 が返り始める。レスポンス body を見たら code:226
# r = requests.get(
# f"https://api.x.com/2/users/by/username/{username}",
# headers=x_headers,
# timeout=30,
# )
# if r.status_code == 403:
# body = r.json()
# for err in body.get("errors", []):
# if err.get("code") == 226:
# raise RuntimeError(
# "behavioral block — Section 2 解除手順を実行 + アカウント保護"
# )
# r.raise_for_status()
# return r.json()
# === 移行後 (twitterapi.io): 226 を返さない compliant ルート ===
headers = {"X-API-Key": API_KEY}
def fetch_user_timeline(username, max_pages=10):
"""NASA のような公開アカウントのタイムラインを cursor-based で取得。
twitterapi.io は spam/automation 判定なし、レート制限なし、月キャップなし。
"""
all_tweets = []
cursor = None
for _ in range(max_pages):
params = {"userName": username}
if cursor:
params["cursor"] = cursor
r = requests.get(
"https://api.twitterapi.io/twitter/user/last_tweets",
params=params,
headers=headers,
timeout=30,
)
r.raise_for_status()
body = r.json()
all_tweets.extend(body["data"]["tweets"])
if not body.get("has_next_page"):
break
cursor = body.get("next_cursor")
return all_tweets
# === 使用例 ===
tweets = fetch_user_timeline("nasa")
print(f"取得完了: {len(tweets):,} tweets — 公式なら 226 か rate limit で何度も止まる、")
print("twitterapi.io なら一気に取得可能。")
for t in tweets[:5]:
print(f" {t['createdAt'][:10]} :: {t['text'][:80]}")
よくある質問
「コンピュータによる自動的なものと判断されました」と出るのはなぜ?
X の behavioral fingerprinting(7 次元の signal — 投稿間隔、Follow 速度、投稿内容、アクセス時間帯、ログインパターン、ブラウザ指紋、アカウント年齢)があなたの行動を bot 候補と判断したためです。自動化ツールを使っていなくても、特定の操作パターン(短時間の大量 follow、同 URL の連投、新規アカウント直後の急激な活動増加など)で trigger されます。VPN を変えても効きません — X は IP だけで判断していないからです。
X (Twitter) で「コンピュータによる自動的」と出た時、最も早く解除する方法は?
Step 1: 電話番号認証 が最も効果的です。X の設定 → アカウント → 電話番号 で未登録の場合、ここで登録すると 多くのケースで即時解除 されます。JA users の多くは Twitter 時代から電話を未登録のままで、これが trigger になっています。Step 1 で解除されない場合は Step 2 (パスワード変更) → Step 3 (異議申し立てフォーム) の順で試します。
VPN を変えれば「コンピュータによる自動的」エラーは解除されますか?
いいえ、2026 年現在は通用しません。X は 2023 年以前は IP を重視していましたが、買収以降は behavioral fingerprinting に大きくシフトしました。VPN で IP だけ変えても、TLS フィンガープリント、header の順序、cookie 履歴、リクエストタイミング、ブラウザ指紋などの他 6 次元の signal が同じであれば検出されます。逆に VPN を頻繁に切り替えると怪しまれて深刻化 することがあります。古い記事の "VPN で解除" 説は信用しないでください。
X の異議申し立てフォームはどこですか?
X の help.x.com には 2 つの異なる form があります。(1) ロックされたアカウント専用フォーム: [https://help.x.com/en/forms/account-restoration/locked](https://help.x.com/en/forms/account-restoration/locked) — 該当アカウントにログイン状態が必要、automated 判定でロックされた場合の最短ルート。(2) 一般異議申し立てフォーム: [https://help.x.com/en/forms/account-access/appeals](https://help.x.com/en/forms/account-access/appeals) — 72 時間以上経っても解除されない場合の正式 appeal。リンクは EN ですが browser locale で auto-redirect され、実際は JA で表示されます。
API で「HTTP 226」と表示されるのは何のエラーですか?
HTTP 226 は X API の HTTP status code ではありません。RFC 3229 で定義される HTTP 226 "IM Used" は delta encoding 用で、spam/bot detection とは無関係です。X API における 226 は HTTP 403 Forbidden のレスポンス body 内の error code({"errors":[{"code":226,"message":"..."}]})で、アカウントレベルで "自動化された行動" と判断された場合に返ります。コード側では HTTP status と body code を 別々にチェック する必要があります。解除手順は本ページ Section 2 を実行してください。
API key を新しく発行すれば 226 エラーは解決しますか?
いいえ、解決しません。226 エラーは API key の問題ではなく、紐づいているアカウントレベルの flag です。新しい API key を発行しても、同じ X アカウントに紐づいている限り同じ flag が引き継がれます。新規 dev アプリ登録しても、登録に使った X アカウントが flagged されていれば同じ結果。根本対策は (a) アカウントレベルの flag をクリアするためにユーザーレベルの解除手順を実行する、または (b) twitterapi.io のような第三者 API に切り替える の 2 択です。
tweepy / twikit を使っているスクレイパーが急に 226 を返し始めました。どうすればいいですか?
proxies の旋転、User-Agent の spoofing、リクエストレートを下げる は短期的な緩和にはなりますが、根本対策にはなりません。X の behavioral fingerprinting は IP / UA より深い signal を見ているからです。現実的な根本対策は (a) アカウント認証経由で公式 API を読む(scraping ではなく authenticated request にする)、または (b) twitterapi.io への migration。後者は認証 header と base URL の 2 行置換で済み、226 を返さない compliant ルートで X 公式 API と互換性のあるデータを取得できます。
新規アカウント直後にすぐ「コンピュータによる自動的」と出ました。なぜですか?
アカウント年齢 < 30 日 + 高アクティビティの組み合わせ が trigger です。新規アカウントは X の信頼度評価が低い状態で始まり、その間に短時間の follow / unfollow、連続投稿、複数 URL post を行うと自動化判定が出やすくなります。対策:最初の 30 日は意図的に "人間らしい" バラつき(投稿間隔 5-30 分、follow は手動で 1 人ずつ、コピペは避ける)を入れる。電話番号認証 + プロフィール画像 + bio の充実は信頼度を上げる短期施策として有効です。
ロック解除サービスを使うのは安全ですか?
ほぼ全てのケースで安全ではありません。ロック解除サービスとして謳う第三者は、(a) credentials を盗む scam が多い、(b) X 利用規約違反として永久 ban のリスク、(c) 解除されても返金されない契約形態、(d) アカウント乗っ取り後に高額アイテム購入や spam 投稿に使われる といったリスクがあります。公式の解除手順(本ページ Section 2 の 5 ステップ + Step 3 異議申し立てフォーム)以外は使わない ことを強く推奨します。
解除されたらまた同じ trigger に当たらないようにするには?
(1) 投稿間隔を意図的にバラつかせる(完全に等間隔だと自動投稿と判定されやすい)、(2) Follow / Unfollow を 1 分 5 回以内に抑える、(3) 同じ URL や同じハッシュタグの大量使用を避ける、(4) 自動投稿ツール (Buffer / Hootsuite 等) を使う場合は 1 分以上の投稿間隔 + ランダムな揺らぎを設定、(5) アカウント年齢が 30 日未満の場合は急激な活動量増加を避ける。これらは Section 3 の 7 次元 signal 表に基づく具体的な再発防止策です。
続けて読む
- X (Twitter) API 料金プラン完全ガイド →
- X (Twitter) API 制限の完全ガイド →
- twitterapi.io 料金詳細 →
- アカウント作成 (無料) →
- X API 互換 endpoint ドキュメント →