Twitter 数据抓取 API:从搜索到批量导出的完整方案
中文开发者在搜「Twitter 数据抓取 API」时,真正想解决的工程问题往往是:怎样在不踩 X 官方风控 + 不维护代理 IP 池 + 不付月费起步 $200 的前提下,批量拿到推文 / 用户 / 关注者 / 互动数据。本文以 TwitterAPI.io 为例,给一份从 0 到批量抓取 100 万条推文的完整工程方案 — 接口选型、代码模板、频率控制、性能优化、成本估算全覆盖。
Twitter(X)数据抓取的核心难点不是「能不能拿到」,而是「能多稳、能多大、多便宜」。官方 X API 2026 年 2 月切到混合计费(月费起步 + 2,000,000 Posts/月硬上限),Basic 层 $200/月、Pro 层 $5,000/月。对于大多数舆情监控、AI 训练、跨境营销分析等批量场景,官方 API 的月费门槛 + 速率窗口锁让接入成本失控。
TwitterAPI.io 的工程定位:面向全球开发者的 SaaS 数据 API,主机名 api.twitterapi.io,约 75 个端点(读 + 常用写入 + 实时推送 + Trends)。按调用次数线性计费(约 $0.15 / 1,000 条推文返回),没有月费、没有月度配额上限、没有强制速率窗口锁。100 万次推文请求月度成本约 $150,跟官方 X API Basic 同等用量对比节省 80%+。
数据抓取的 3 种典型 pipeline
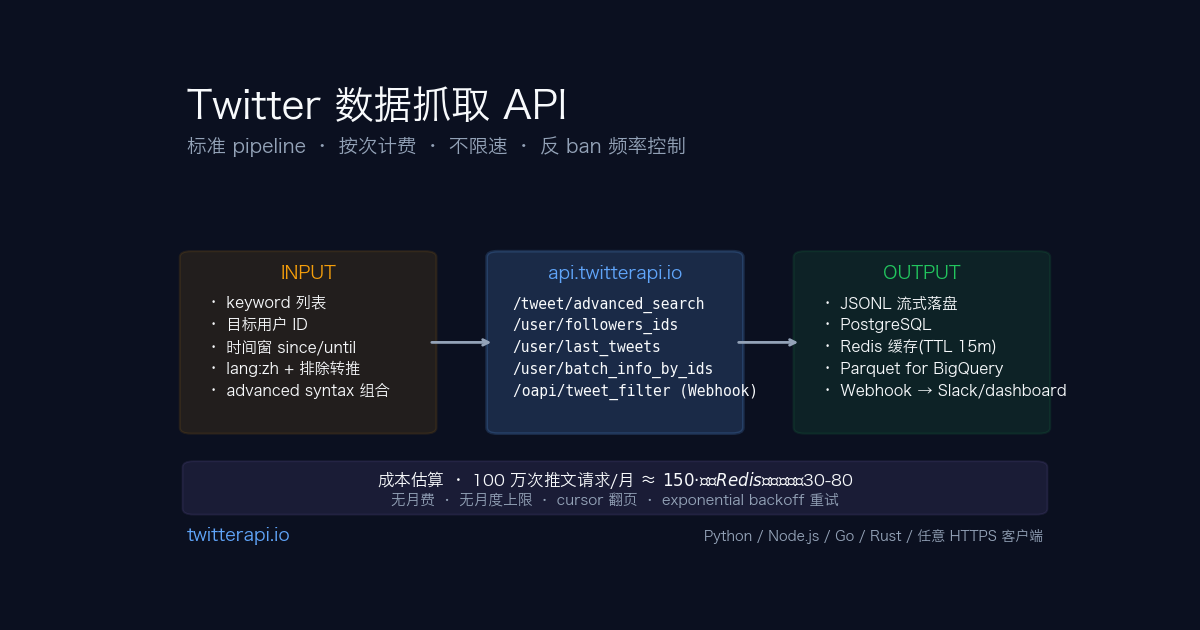
实际工程中,Twitter 数据抓取大致分 3 种 pipeline,每种对应不同的接口组合 + 成本模型。
Pipeline A:关键词全量历史扫描。目标:把过去 N 天提到某 keyword(品牌 / 话题)的所有公开推文一次性抓下来。主用 /twitter/tweet/advanced_search + next_cursor 翻页。X 的 advanced search syntax 支持 since:2026-01-01 until:2026-05-27 keyword lang:zh -is:retweet,可精准框定时间窗 + 语言 + 排除转推。10 万条推文规模,成本 ≈ 10 万 × $0.00015 = $15。
Pipeline B:目标用户深度挖掘。目标:抓某账号(KOL / 竞品 / 客户)的全部历史推文 + 粉丝列表 + 关注列表 + 互动数据。主用 /twitter/user/info 拿基础资料 → /twitter/user/last_tweets 拿全推文 timeline(配合 cursor 翻页) → /twitter/user/followers_ids 拿粉丝 ID 数组(轻量端点,省 80% 流量) → /twitter/user/followings 拿关注列表。1 个 KOL 完整数据 ≈ 5-20 美元(依粉丝量)。
Pipeline C:实时增量监控。目标:某 keyword / 某账号有新推文立即推送到自建系统。主用 /oapi/tweet_filter/add_rule 注册规则 + Webhook URL 接收 push,完全省去 polling 成本。规则书写跟 advanced search syntax 一致(from:openai OR @anthropic)。延迟数秒到数十秒,适合舆情监控 / 实时 dashboard。
Python 批量抓取脚本(完整可跑)
下面是 Pipeline A 的完整 Python 实现 — 批量抓取过去 7 天提到 "openai" 的中文推文,自动 cursor 翻页 + 速率自控 + JSONL 流式写盘。
频率控制 — 避开 X 反风控的 5 条规则
TwitterAPI.io 本身没有强制速率窗口(不像官方 X API 的 15 分钟窗口锁),但 X 平台对写入操作(发推 / 点赞 / 转推 / 关注)仍有风控。读取操作(搜索 / 用户信息 / 互动数据)基本不会触发用户账号风控,因为是服务商对官方接口的合规调用,不是你账号的行为。
规则 1:写入操作按人类节奏。每小时点赞 < 30、每天发推 < 50、每天关注 < 100。间隔随机化(time.sleep(random.uniform(60, 180)) 而不是固定 60)。
规则 2:DM 操作完全不要碰。API 发 DM 极易触发账号封禁,TwitterAPI.io 主动不开放此接口(产品策略保护用户账号)。需要 DM 的业务只能走官方 X API OAuth 且做严格频率管控。
规则 3:读取批量也要节流。虽然 TwitterAPI.io 没硬限速,但服务端有保护机制 — 单 API Key 短时间内 > 100 QPS 可能短暂限流。批量抓取建议控制在 30-50 QPS 内,既稳又便宜(避免突发触发服务端节流后的重试浪费)。
规则 4:Cursor 翻页而非 offset。所有列表端点用 next_cursor 翻页(性能稳定 + 一致性保证),不用旧式 page 数字翻页。
规则 5:重试用 exponential backoff。HTTP 429 / 5xx 重试时按 0.5s → 1s → 2s → 4s 退避,不要立即 retry。最多 5 次,超过后落到 dead-letter queue 人工查。
性能优化 — 实测 5 倍成本下降的 3 条措施
在某品牌出海舆情监控项目里,这 3 条措施把月度 API 成本从约 $400 降到 $80(每月抓 50 万条推文 + 5,000 个 KOL 资料)。
优化 1:Redis 缓存热点查询(TTL 15 分钟)。对高频复用的查询(知名 KOL 的最近推文、热门关键词搜索)做 Redis 缓存。@openai 的最近 20 条推文 5 分钟内可能被 dashboard 多个 widget 请求 10+ 次 — 一次抓取 + 9 次 cache hit 直接省 90% 调用。
优化 2:用轻量端点替代完整端点。需要粉丝 ID 列表时用 /twitter/user/followers_ids(只返 ID 数组 + cursor),不要用 /twitter/user/followers(每个 ID 都附带完整 profile)。同样数据量,流量节省 80% 以上,服务端也更快返。
优化 3:dedup 后再批量调用。抓取流程里如果有 for user in 500_users: call_user_info(user) 的循环,先检查 user 是否已在自建库里 + 是否过期(例如 7 天内拿过的 user info 就不再重抓)。dedup 后实际调用量可能只剩 10-15%。
辅助:监控 + 预警。后端 Prometheus / Grafana 记录 api_call_total{endpoint=...} counter,每天 dump 一次,对比当日预算。某个 endpoint 异常升高(可能是 bug 导致循环调用)立即 alert。
和 Tweepy / snscrape / 自建爬虫的对比
中文社区常见 3 种「自己抓 Twitter」的路径,跟 TwitterAPI.io 横向比较:
Tweepy(Python 官方 SDK):Tweepy 是 wrapper 不是数据源 — 底下走的还是官方 X API,继承所有 tier 限制 + 月费门槛。Tweepy 写法干净,但解决不了「便宜 + 不要审核」的工程问题。适合已经付 X API 月费 + 不嫌等审核的项目。
snscrape(Python 第三方):不走官方 API,直接抓 X 网页 — 早期(2022 前)非常好用,但 X 现在严格反爬,snscrape 经常被封 IP / 限频。需要自建大量代理池才能稳定,综合成本未必比商业 API 便宜,而且法律灰区(网页抓取 vs 服务商 API 调用的合规性质完全不同)。
自建 Playwright 爬虫:用 headless browser 模拟真实用户浏览 X 页面解析 DOM。性能极差(单页几秒)+ X 反爬升级时全线挂(每次都要改 selector)+ 风控严格(频繁触发 captcha)。适合极小批量(< 1000 条/天)的 PoC,不适合生产。
TwitterAPI.io:商业 SaaS API,服务商承担合规 + 反爬 + 代理池维护 + endpoint 稳定性。对调用方而言就是「发 HTTPS 请求拿 JSON」的简单工程接口。代价是按次付费(读类约 $0.15/1000 条),适合任何中型规模生产抓取项目。
实际选型决策树:
- 已付 X 官方 API 月费 + 不嫌长审核 → Tweepy
- 极小批量 PoC / 学术研究 → snscrape(但承担法律 + 稳定性风险)
- 生产环境 + 中等批量(月 10 万-1000 万次)+ 想要稳定可预算 → TwitterAPI.io
数据持久化 + 增量更新策略
抓取本身只是第一步,真正用起来需要持久化 + 增量更新机制。常见架构:
Storage 层:推文存 PostgreSQL(tweet_id PK + JSONB 字段存原始 payload + 抽取的 indexed 字段如 created_at / author_id / lang),用户存 PostgreSQL 或 Redis(profile + last_synced 时间戳)。批量历史导出可用 Parquet(列式压缩,适合后续 BigQuery / DuckDB 分析)。
增量更新策略:每个 user 维护 last_tweet_id_synced,下次只抓 since_id=last_tweet_id_synced 之后的新推。/twitter/user/last_tweets 支持这个参数。粉丝列表 6-24 小时 refresh 一次(粉丝变化没那么快,过度抓取浪费成本)。
版本控制:tweets 是 immutable 资源(发出后不会变,除非被删),所以只需 INSERT IGNORE。用户资料 / 粉丝数会变,可以保留历史(user_profile_snapshots 表 + 每次 refresh 加一条),做时序分析时有用。
Webhook + 写入混合:实时 Webhook 推送新推文写入 PostgreSQL,daily batch 用 advanced_search 做去重补漏(catch 极短窗口内 Webhook 漏掉的)。这种 hybrid 比纯 polling 便宜 80%,比纯 webhook 稳定 100%。
成本估算 — 3 个典型项目规模
下面给 3 个不同规模项目的实际成本估算(按 TwitterAPI.io 公开定价计算)。
小型 PoC(月度 < 10 万次调用):个人开发者跑舆情 PoC、学术研究采样、小品牌出海试水。月成本 < $15。新账号 $1 试用额度可覆盖第一周完整试用。
中型项目(月度 50-300 万次调用):中型 SaaS 工具 / 中等 KOL 监控平台 / 出海电商品牌矩阵舆情。月成本 $75-$450。配合本文性能优化 3 条措施可压到 $40-$200(优化空间大)。
大型项目(月度 500-2000 万次调用):大型舆情平台 / 加密项目实时情报 / AI 训练语料持续采集。月成本 $750-$3,000。比官方 X API Pro 层 $5,000/月起步 + 还有 2M Posts/月硬上限 划算很多。规模大可联系 enterprise 套餐拿 volume discount。
ROI 参考:某加密项目用 TwitterAPI.io 监控 300 个 KOL,月度调用 800 万次,月成本 $1,200;同等数据若走官方 X API Pro 需 $5,000/月 + 仍受 2M Posts 月度上限制约。年度差额 $45,600,够 PM 一年工资 1/3。
# 批量抓取过去 7 天提到 "openai" 的中文推文 → 写 JSONL
# 需求:Python 3.10+ + requests + tqdm + python-dateutil
import json, os, time, random
import requests
from datetime import datetime, timedelta, timezone
from tqdm import tqdm
API_KEY = os.environ["TWITTERAPI_IO_KEY"]
HEADERS = {"X-API-Key": API_KEY}
since = (datetime.now(timezone.utc) - timedelta(days=7)).strftime("%Y-%m-%d")
until = datetime.now(timezone.utc).strftime("%Y-%m-%d")
query = f"openai lang:zh since:{since} until:{until} -is:retweet"
output_path = "openai_zh_last_7d.jsonl"
cursor = ""
total = 0
with open(output_path, "w", encoding="utf-8") as f, tqdm(unit="tweet") as pbar:
while True:
# 节流 — 服务端没硬限速,但批量建议 30-50 QPS
time.sleep(random.uniform(0.02, 0.05))
try:
r = requests.get(
"https://api.twitterapi.io/twitter/tweet/advanced_search",
params={"query": query, "queryType": "Latest", "cursor": cursor},
headers=HEADERS, timeout=30,
)
r.raise_for_status()
except requests.HTTPError as e:
# exponential backoff for 429/5xx
if e.response.status_code in (429, 500, 502, 503):
wait = min(2 ** pbar.n_retries if hasattr(pbar, 'n_retries') else 1, 60)
time.sleep(wait)
continue
raise
body = r.json()
tweets = body["data"]["tweets"]
for t in tweets:
f.write(json.dumps(t, ensure_ascii=False) + "\n")
total += len(tweets)
pbar.update(len(tweets))
cursor = body["data"].get("next_cursor", "")
if not cursor or not tweets:
break
print(f"done: {total} tweets → {output_path}")
# 成本估算:total 条推文 × $0.00015 = 实际 API 费用常见问题
TwitterAPI.io 限速吗?批量抓取会被封吗?
服务端没硬限速窗口(不像官方 X API 的 15 分钟窗口锁),但单 API Key 短时间 > 100 QPS 可能短暂限流。批量抓取建议控制 30-50 QPS。读取操作(搜索 / 用户信息 / 互动数据)基本不会触发任何账号风控,因为是服务商的合规接口调用。只有写入操作(发推 / 点赞 / 转推 / 关注)需要按人类节奏控制频率避开 X 平台风控。
和官方 X API 相比成本差多少?
100 万次推文请求 / 月在 TwitterAPI.io ≈ $150;官方 X API Basic 月费 $200(含 2M Posts/月上限,超出后不可购买)。500 万次场景:TwitterAPI.io ≈ $750;官方 X API Basic $200 + 超出 300 万 × $0.005 overage = $15,200。5 倍量级官方就贵 20×+。中型以上项目用第三方 API 经济性显著。
支持哪些 X advanced search syntax?
/twitter/tweet/advanced_search 端点支持 X 原生 advanced search 全套 syntax — keyword、from:user、to:user、@mention、#hashtag、since:YYYY-MM-DD until:YYYY-MM-DD 时间窗、lang:zh / en / ja 语言过滤、-is:retweet -is:reply 排除类型、min_faves:100 min_retweets:50 互动门槛、url:domain.com 含特定链接、布尔组合(A OR B AND C)。组合使用可精准定位目标推文。
数据实时性怎么样?
advanced_search 端点 query 出来的新推文一般在发出后 5-30 秒可获取(取决于服务端 indexing 队列)。如需秒级实时,用 Webhook 注册过滤规则(/oapi/tweet_filter/add_rule),匹配的新推文会 push 到你的 callback URL,延迟通常 2-10 秒。WebSocket 持久连接同样秒级 push,适合前端 dashboard 直连。
能拿到 deleted tweets 吗?
如果推文已被删除 / 账号已被封,X 平台数据源就拿不到了。TwitterAPI.io 没有自建历史存档(那是 Twitter Archive 类产品的事),所以删除后无法 retroactive 拿到。如果业务要保留历史,你的抓取系统应该 immutable INSERT IGNORE 写自己的 PostgreSQL,从你抓到的那一刻起,即使后续 X 删了你本地仍有快照。
Python 之外的语言怎么接?
任何能发 HTTPS 请求的语言都行。Node.js 用 axios / node-fetch、Go 用 net/http、Java 用 OkHttp、Ruby 用 Net::HTTP、PHP 用 curl、Rust 用 reqwest。Dashboard 提供 cURL + Python + Node.js 三种示例代码模板。接口是标准 RESTful + JSON,不依赖任何特定语言 SDK。
数据合规怎么办?GDPR / PIPL 适用吗?
抓到的是 X 平台的公开数据(任何人不登录也能看到的推文 / 用户资料 / 互动数),但「公开数据 ≠ 没有合规义务」。如果数据中包含可识别自然人的个人信息(用户名、profile picture、地理位置等),处理这些数据需符合各地法律:中国境内主体涉及大量境内自然人个人信息 → 《个人信息保护法》《数据出境管理规定》;欧盟用户数据 → GDPR;美国加州用户 → CCPA。建议项目接入前让法务团队评估具体业务场景。本回答不构成法律建议。
新账号能跑多久?
新账号默认 $1 试用额度(不需要绑卡),可跑约 6,000 次基础接口调用 — 够个人开发者 PoC 一周左右(单 KOL 完整数据 + advanced search 几百次 + 测试调用)。试用够用后充值,没有最低充值门槛,$10 起即可。月度调用量无硬上限,只看你充值的余额够不够扣。
继续阅读
- /pricing
- /docs
- /zh-CN/blog/twitter-api-jiekou
- /zh-CN/blog/twitter-api-zhongzhuan-fuwu
- /blog/tweepy-vs-twitterapi-io-python-migration