Getting Real Political Data From Twitter (X)

Twitter — now X — is still where politicians announce, journalists break news, and electorates argue. That makes it one of the richest sources of political data anywhere: every official statement, every reaction, every shift in tone, timestamped and public.
Getting that data has become the hard part. The free academic-research access that powered a decade of political-science papers is gone, the API is now metered and priced for enterprises, and a lot of the public datasets researchers lean on are frozen snapshots that no longer rehydrate cleanly.
The sections below cover what political data on X consists of, the three routes to collecting it and what each costs, and the failure modes — bias, bots, deletions — that quietly wreck a dataset built without them in mind.
What Counts as Political Data on X
"Political data" from X is a loose label covering several distinct datasets that happen to share a platform. A collection plan has to name which one it is after:
Official-account output. The posts of politicians, parties, government agencies and candidates — a clean, high-signal record of what official actors said and when. Many of these accounts carry a government or verified label, which makes them easy to filter to.
Issue and election discourse. Everything the public posts about a candidate, a bill, a hashtag or an election — far larger, far noisier, and the basis of most sentiment and public-opinion work.
Engagement and diffusion. Who amplified what, how fast, and how far — reposts, replies, quote-posts and the timing between them. This is how researchers study influence and the spread of narratives.
Derived signals. Sentiment, stance, topic and bot-likelihood scores computed on top of the raw posts. These are produced by your analysis, not handed to you — but they are usually the actual research output.
Each of these needs a different query and a different volume budget. Conflating them is the first mistake; a politician-accounts dataset is a few thousand posts a month, while election-discourse collection can be millions.
Three Ways to Get It
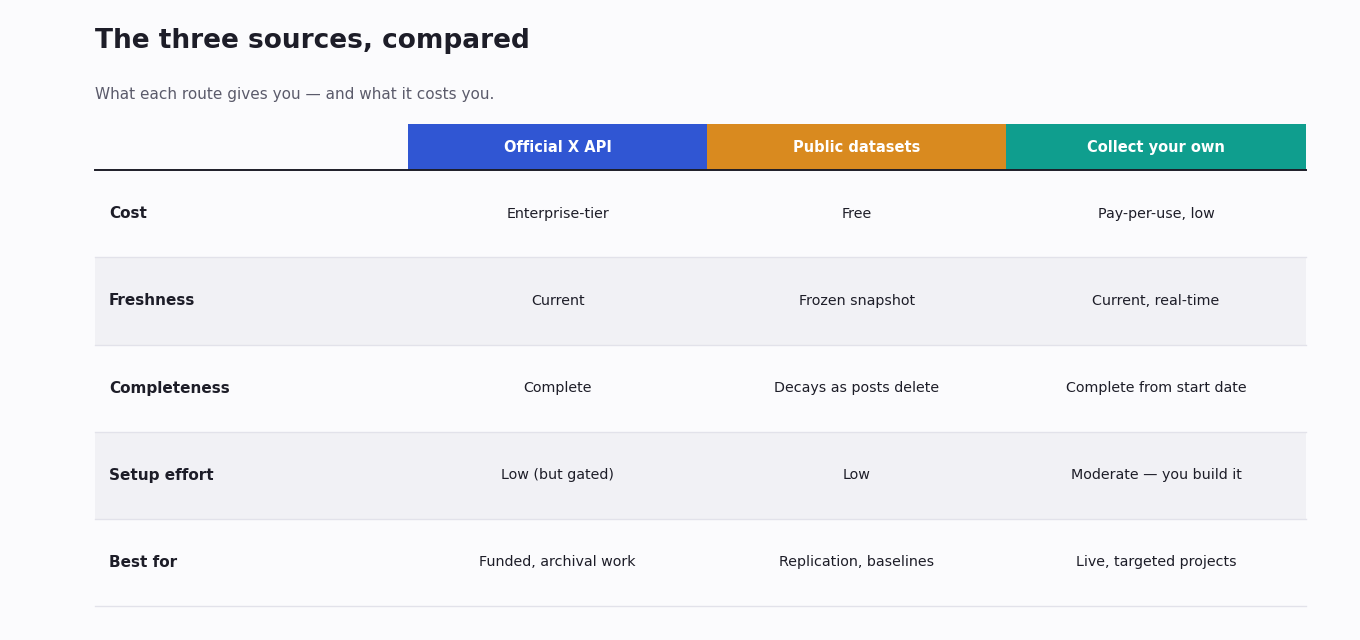
There are three real routes to political X data, and serious projects usually combine them.
The official X API is authoritative and complete, but priced for enterprises since the research tier closed. Public research datasets are large, free and already collected, but frozen in time and increasingly hard to rehydrate. The third route is to collect the data yourself through a third-party API: pay-per-use, current, and shaped to your exact question, in exchange for building the collection.
A common combination: a public dataset as the historical baseline, your own forward collection for everything after that dataset's window ends, and a few targeted official-API pulls only where completeness is non-negotiable. Each route covers another's blind spot.
The figure below lays the three side by side. The rest of this guide walks each one, then covers the pitfalls that apply no matter which you choose.
The Official X API — and Why Research Got Harder
For years X (then Twitter) ran a dedicated Academic Research access track: free, generous, with full-archive search. A large share of the published political-science literature on social media was built on it.
That track was discontinued. New developers now get the same metered, pay-per-use API as everyone else — billed per request, with no low flat tier and an Enterprise contract that starts in the tens of thousands of dollars a month. For a research project that needs millions of historical posts, the official API is, in practice, priced out.
The official API is still the authoritative source — it is X's own data, complete and first-party. If your work genuinely requires that completeness and you have institutional funding, it remains the gold standard. For most political-data work at a normal budget, it has stopped being the realistic answer.
Public Election Datasets
Researchers have published large public datasets around major elections — multi-million-post collections tracking candidates, events and hashtags — along with curated databases of legislators' accounts across many countries. They are free, peer-reviewed, and a reasonable starting point if your question fits one that has already been collected.
Two limits matter. First, they are frozen: a dataset covers a fixed window and stops, so it cannot answer anything about what happened after collection ended. Second, most are distributed as tweet IDs, not full posts — to comply with platform terms, you get a list of IDs and must "rehydrate" them by fetching each through an API.
Rehydration used to be free and complete. It is now neither: it runs through the same paid API, and every post deleted since the dataset was built comes back empty — and politically sensitive posts are deleted at a high rate. A years-old election dataset can rehydrate to a fraction of its original size, skewed toward whatever was never taken down.
Use public datasets for what they are good at — a historical baseline, a validation set, a replication target — and do not expect them to be either current or complete.
Collecting Politician-Account Data Yourself
The cleanest political dataset to build yourself is official-account output. You start from a list of handles — a chamber of a legislature, a cabinet, a slate of candidates — and pull each account's posts.
Through a third-party API this is cheap and current. A from: search collects an account's posts; an account-timeline endpoint does the same by handle. A few hundred official accounts polled daily is a small, steady volume — well under what election-discourse collection costs — and it gives you a complete, first-party record of what those actors posted.
Two fields make this dataset more useful. The account object carries a verification type, so you can confirm an account is a genuine government or official one rather than a parody or impersonator. And because you are collecting forward, in real time, you capture posts before they can be deleted — turning the deletion problem from a data loss into a data point you can study.
Collecting Election and Issue Discourse
Public discourse — what everyone, not just officials, is posting — is the larger and harder collection. It is a keyword problem: you define a query (candidate names, hashtags, issue phrases), pin a language and a date range, and page through the results.
Two design decisions shape the dataset before you collect a single post. Query framing is itself a bias: the hashtags and phrases you choose decide whose conversation you capture — search only one side's hashtag and you have measured one side. Collect a balanced, documented keyword set. Volume is the budget: issue discourse runs to millions of posts, so scope a date range and a sampling rate up front rather than letting an open query run. A focused query over a tight window — a single debate night, one bill's news cycle — is often a better dataset than a sprawling one: cheaper to collect, cleaner to analyse, and pointed at a sharper question.
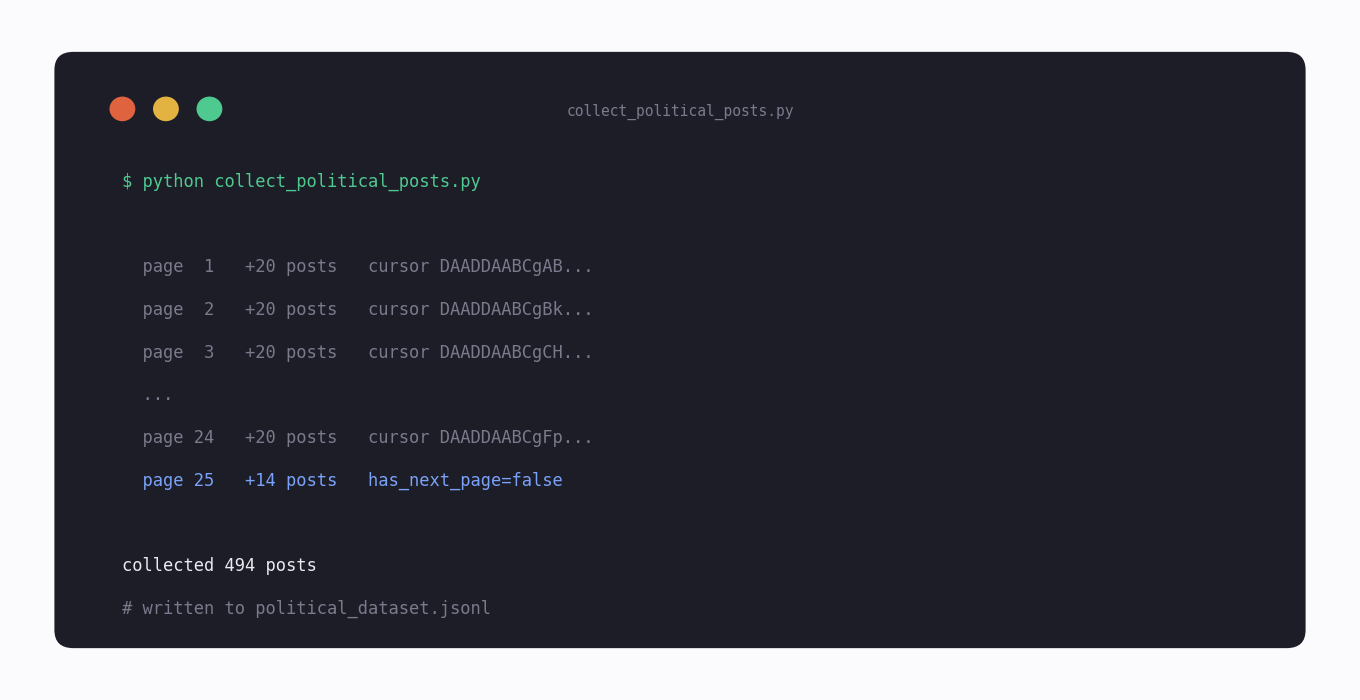
The worked example below shows the shape of it: an advanced search over a political query, language- and recency-filtered, paging through results with a cursor so a large collection runs as one resumable job.
Code: Collecting Posts for a Political Query
The script registers an advanced-search query — here a candidate handle, but it works the same for a hashtag or an issue phrase — and pages through every match with the response cursor, writing each post to your own storage. Swap the query for a from: chain of official handles and the same loop becomes a politician-account collector.
Pitfalls in Political Twitter Data
X users are not the electorate. The platform's user base skews by age, geography, education and politics, and it is not the population that votes. Treat X data as a measure of online discourse, not a poll: forecasts that conflated the two have a poor track record.
Bots and coordinated activity. Political topics attract automated and coordinated posting more than almost any other subject. Raw post counts and raw sentiment are inflated by it; a bot-likelihood filter is not optional for serious work.
Deleted and edited posts. Politicians delete posts at a high rate, and a deletion is itself a finding. A dataset collected after the fact silently omits them; only forward collection captures a post before it can vanish.
Keyword framing bias. Covered above, and worth repeating because it is the most common flaw — the query is a hypothesis, and an unbalanced query produces an unbalanced dataset no amount of later analysis can fix.
Sampling opacity. If a dataset was built from a sampled stream, you rarely know exactly how it was sampled. Document your own collection — query, dates, rate, API — so your work is reproducible even when your sources were not.
import requests
API_KEY = "your_api_key"
BASE = "https://api.twitterapi.io/twitter/tweet/advanced_search"
# Any advanced-search query works here: a candidate handle (from:...),
# a hashtag, or an issue phrase. lang: and date filters keep the
# collection scoped — political discourse is large, so scope it.
query = "(election OR ballot OR vote) lang:en"
def collect(query, max_pages=25):
posts, cursor = [], ""
for _ in range(max_pages):
r = requests.get(
BASE,
params={"query": query, "queryType": "Latest", "cursor": cursor},
headers={"X-API-Key": API_KEY},
timeout=30,
)
r.raise_for_status()
data = r.json()
for t in data.get("tweets", []):
posts.append({
"id": t["id"],
"created_at": t["createdAt"],
"author": t["author"]["userName"],
"verified_type": t["author"].get("verifiedType"),
"text": t["text"],
"reposts": t["retweetCount"],
})
if not data.get("has_next_page"):
break
cursor = data["next_cursor"]
return posts
rows = collect(query)
print(f"collected {len(rows)} posts")
# Write rows to your own storage — that file is your political dataset.
Questions readers ask
Can I still get political data from Twitter for research?
Yes, but the route changed. The free academic-research API track was discontinued, so most researchers now either work from public datasets collected earlier or collect their own through a third-party API that bills pay-per-use. The official X API is still authoritative but is priced for enterprises.
How can I tell an X account is a real government or official one?
The account object returned by the API carries a verification type. Genuine government and official accounts are labelled distinctly from ordinary verified accounts, so you can filter a politician watchlist down to confirmed official accounts and screen out parody and impersonator accounts before they enter your dataset.
What public datasets of political tweets exist?
Researchers have published large public datasets around recent major elections — multi-million-post collections tracking candidates and hashtags — and curated databases of legislators' accounts across many countries. They are free and peer-reviewed, but frozen in time and usually distributed as tweet IDs that must be rehydrated through an API.
Why can't I just rehydrate an old election dataset?
You can, but two things have changed. Rehydration now runs through a paid API rather than a free one, and any post deleted since the dataset was built returns empty. Because politically sensitive posts are deleted at a high rate, an old dataset often rehydrates to a fraction of its original size, skewed toward what was never removed.
Can I recover political tweets that were deleted?
Not after the fact — once a post is deleted, no API returns it. The only reliable way to hold a politician's deleted posts is to have collected them before deletion, by polling official accounts forward in real time. A dataset built afterwards simply omits them, so if deletions matter to your work, forward collection is the method.
How do I collect tweets from specific politicians?
Start from a list of official handles and pull each account's posts — a from: advanced search, or an account-timeline endpoint by handle. Through a third-party API this is cheap because the volume is small. The account's verification type lets you confirm it is a genuine government or official account, not a parody.
How much does collecting political Twitter data cost?
Through a pay-per-use third-party API, roughly $0.15 per 1,000 posts and $0.18 per 1,000 profiles, with no monthly minimum. A politician-accounts dataset is small — a few dollars a month. Broad election-discourse collection runs to millions of posts, so scope the date range and sampling rate to control the bill.
Can Twitter data predict election results?
Treat that claim with caution. X users are not a representative sample of the electorate — they skew by age, geography and politics — so X data measures online discourse, not vote intention. It is valuable for studying narratives, agenda-setting and reaction, and unreliable as a standalone forecast.
How do I handle bots in political Twitter data?
Assume they are present — political topics attract automated and coordinated posting more than most subjects. Raw post and sentiment counts are inflated by it, so apply a bot-likelihood filter before analysis, and report what you filtered. Treating raw volume as genuine public opinion is a common and serious error.
Is it legal to collect political tweets?
Collecting and analysing public posts for research or journalism is generally accepted, and public-interest political accounts are squarely public. Follow the API provider's terms, respect deletions and protected accounts, and handle any personal data under the applicable rules — but public political speech on a public platform is the least contentious category to study.
Continue
- /
- /twitter-api-for-research
- /blog/twitter-api-with-python
- /blog/twitter-monitoring
- /blog/deleted-tweet-search
- /pricing
Stop reading. Start building.
Starter credits cover real testing on real data. Google sign-in, no card, no application queue.
Get an API key