Twitter Sentiment Analysis in Elections: Guide
Twitter Sentiment Analysis in Elections: Guide
Twitter sentiment analysis is reshaping election campaigns by providing real-time insights into voter opinions through social media posts. Instead of relying on traditional surveys, campaigns can now analyze tweets to monitor public sentiment, detect sudden shifts, and refine strategies almost instantly. Here's the key takeaways:
- What is Sentiment Analysis? It's the process of determining if a text conveys positive, negative, or neutral emotions using tools like Natural Language Processing (NLP) and machine learning models.
- Why Twitter? With 300 million active users and concise 280-character posts, Twitter offers a rich source of unfiltered, real-time voter reactions.
- How Campaigns Use It: Analyze regional support, identify key voter concerns, and predict election outcomes using sentiment trends.
- Data Collection Tools: Platforms like TwitterAPI.io simplify data gathering with features like live streams and historical tweet archives.
- Challenges: Noise in data (e.g., sarcasm, slang), geographic biases, and multilingual content can complicate analysis.
- Best Practices: Clean data thoroughly, use models like VADER or BERT for accuracy, and balance geographic data to avoid skewed results.
Realtime Twitter Sentiment Analysis using Pretrained Model (NLP) | Python
sbb-itb-9cf686c
Collecting Election Data from Twitter
Gathering Twitter election data requires reliable tools, precise filtering, and adherence to ethical guidelines. The accuracy of insights depends on the quality of the data collected. This section dives into how to effectively collect and refine election-related data from Twitter, building on the fundamentals of tweet sentiment analysis.
Using TwitterAPI.io for Data Collection

TwitterAPI.io simplifies Twitter data collection by removing the need for complex authentication processes or developer account approvals. Instead of waiting for lengthy approvals, you can start collecting data in just minutes.
The platform offers several integration methods, making it flexible for different needs. For example:
- REST API: Ideal for batch processing historical election data.
- WebSockets: Perfect for live dashboards that track real-time sentiment shifts.
- Webhooks: Automatically push data to your endpoint when tweets meet specific election-related criteria.
For live data, the stream_filter endpoint delivers a fast, high-throughput stream at 100 queries per second (QPS), which is especially useful for capturing voter reactions during debates or election night. If you need historical data, the tweet_advanced_search endpoint provides full-archive access, allowing you to retrieve tweets from past election cycles using specific keywords or user filters.
TwitterAPI.io boasts impressive performance metrics, including over 1,000 QPS, a 99.99% uptime guarantee, and an average response time of around 800 milliseconds. Pricing is pay-as-you-go, starting at $0.15 per 1,000 tweets.
"Unlike official Twitter APIs, our service offers 96% cheaper pricing, high performance (~800ms response time), and high throughput (1000+ QPS)." - TwitterAPI.io
Filtering Tweets for Election Content
After collecting data, effective filtering ensures you focus on tweets relevant to elections.
Start by combining keywords such as candidate names, political party names, and campaign-related hashtags like #Election2024. This helps capture tweets that are contextually significant. Research supports the value of this approach - one analysis of 76 studies found that about 78% of prediction models accurately forecasted election outcomes based on Twitter sentiment.
To refine your data further, apply specific filters:
- Temporal Filters: Segment tweets based on timing (e.g., pre-election, during the election, and post-election) to study shifts in voter sentiment.
- Geographic Filters: Use location data to analyze regional sentiment, but keep in mind that user location fields can be inconsistent. A mapping dictionary (e.g., linking "CA" to "California") can help resolve ambiguities.
- Language Filters: Focus on relevant languages, such as English, using queries like
lang:en. - User-Specific Queries: Narrow down tweets from specific accounts with filters like
from:candidate_name.
To maintain data quality, exclude bot accounts and spam. This ensures your analysis reflects genuine voter opinions rather than automated or irrelevant content.
Ethics and Compliance in Data Collection
Handling Twitter data for election analysis comes with critical ethical and legal responsibilities. Always follow platform guidelines to avoid disruptions like Error 226, which can temporarily block your data collection pipeline during crucial election periods.
To ensure compliance:
- Store raw JSON data and anonymize user information to protect privacy.
- Avoid publishing individual tweets that could identify specific users.
- Follow GDPR-compliant storage practices, as outlined by TwitterAPI.io, to meet academic research standards and secure Institutional Review Board (IRB) approval.
Preparing Twitter Data for Analysis
Raw Twitter data can be chaotic. Tweets often include URLs, hashtags, emojis, typos, and slang, all of which can confuse sentiment analysis models. To accurately assess voter sentiment, it's important to clean and standardize the data. Once you've accessed your Twitter data, follow these preprocessing steps to ensure your analysis focuses on genuine sentiment.
Cleaning and Normalizing Text Data
Start by removing elements that don't contribute to sentiment analysis. Using Python's re library, strip out URLs (like those starting with "https://"), HTML tags, and user mentions (e.g., "@username"). These elements tend to clutter the data without adding meaningful insights into voter opinions.
Next, convert all text to lowercase. This prevents the model from interpreting "Happy" and "happy" as two different words. Additionally, eliminate non-alphabetic characters and normalize elongated words (e.g., turning "looooove" into "love") to maintain consistency in the vocabulary.
Emojis can carry strong emotional signals, so rather than removing them, convert them into text descriptions with tools like emoji.demojize. For instance, "😊" becomes ":smiling_face:", which retains its sentiment value for analysis. Similarly, expand common Twitter abbreviations - turn "gr8" into "great" or "can't" into "cannot" - to create a standardized vocabulary.
After cleaning, remove stopwords such as "the", "and", or "is." However, because standard stopword lists might be too aggressive for social media text, consider customizing your list to better reflect political discourse.
Once the text is cleaned and standardized, you're ready to break it into smaller components for further processing.
Tokenization and Lemmatization
Tokenization is the process of splitting cleaned text into individual words or tokens, making it easier to analyze. Libraries like nltk offer functions like word_tokenize to effectively break tweets into manageable units.
Lemmatization takes this a step further by reducing words to their base or dictionary form. Unlike stemming, which can crudely chop off word endings, lemmatization considers the context and part of speech. For example, it can correctly convert "better" to "good" or "running" to "run", ensuring that related words are treated as the same. This step reduces data sparsity and improves the performance of sentiment models.
"The goal of lemmatization is to normalize words by converting them to a common form so that words with similar meanings are grouped together." - Mahesh Tiwari, AI Mind
To get the most out of lemmatization, perform Part-of-Speech (POS) tagging beforehand. By mapping tokens to categories like nouns, verbs, adjectives, and adverbs (using tools like WordNet), the lemmatizer can better interpret each word's role in a sentence.
Handling Multilingual Tweets
Once the text is cleaned and tokenized, it's time to address multilingual content. Election campaigns often spark tweets in multiple languages. Start by detecting the language of each tweet using tools like langdetect. This allows you to either focus on a specific language (e.g., English for U.S. elections) or send non-English tweets to a translation service for further analysis.
In a study conducted in July 2023, researchers Priyavrat Chauhan, Nonita Sharma, and Geeta Sikka analyzed 258,891 tweets from the 2019 Indian General Election. They discovered that 60% of raw tweets contained irrelevant media content, which could distort sentiment results. This highlights the importance of filtering and language-specific preprocessing.
For elections with significant linguistic diversity, consider using multilingual models like XLM-T, which are trained on Twitter data in various languages. These models can better capture subtle sentiment cues across languages. Additionally, ensure that emojis and Unicode characters are preserved during preprocessing, as they often convey universal emotional signals.
Methods for Sentiment Analysis
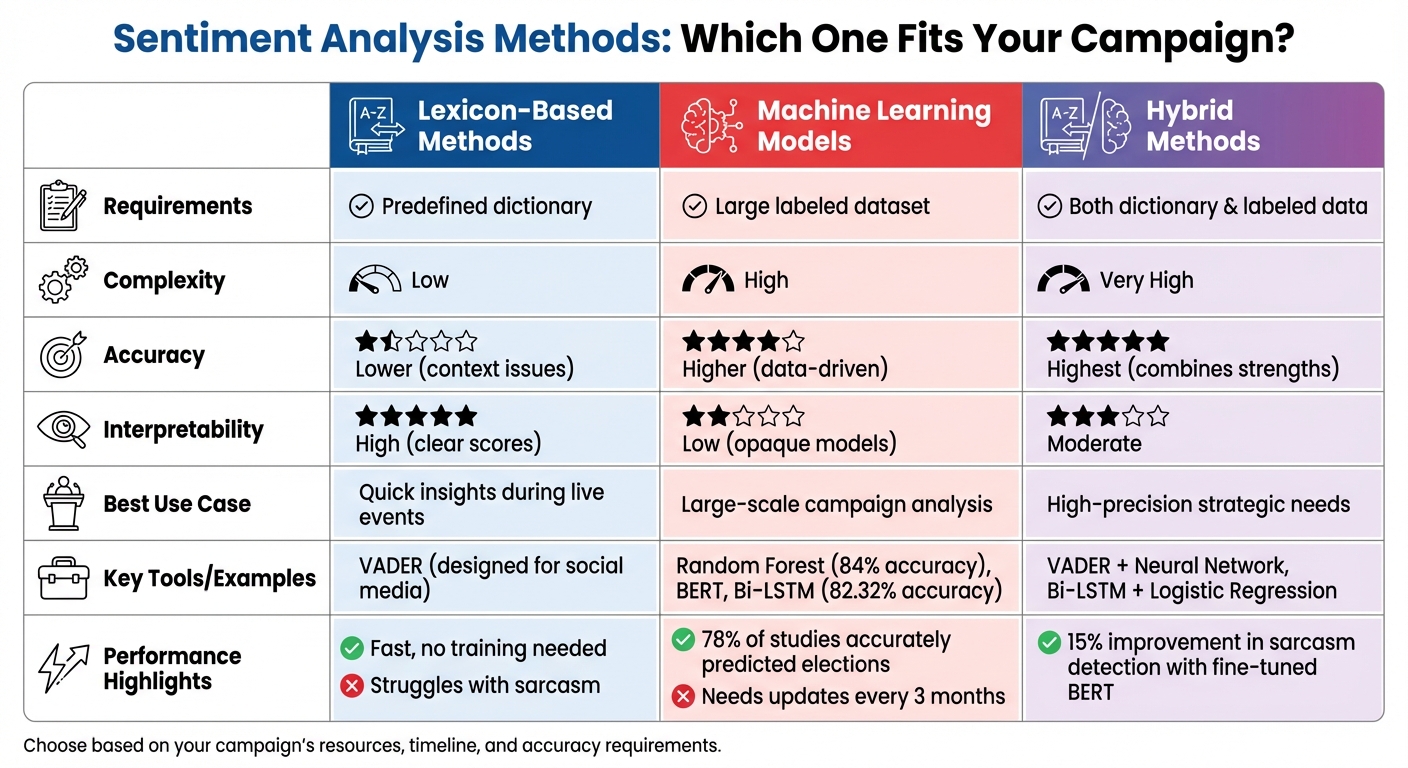
Comparison of Sentiment Analysis Methods for Election Campaigns
When it comes to monitoring election campaigns, choosing the right sentiment analysis method is key. Using cleaned and normalized data, these methods help uncover detailed sentiment trends. The three main approaches are lexicon-based methods, machine learning models, and hybrid methods that combine both. Each option has its own pros and cons, depending on your campaign's goals, resources, and accuracy needs.
Lexicon-Based Sentiment Analysis
Lexicon-based methods rely on predefined dictionaries where words are assigned sentiment scores. The process involves breaking down tweets into individual words, assigning a polarity score from the dictionary, and calculating an overall sentiment score. For example, the AFINN lexicon includes over 3,300 English terms, each with a sentiment value.
For Twitter election analysis, VADER (Valence Aware Dictionary and sEntiment Reasoner) is highly effective. Designed specifically for social media, VADER accounts for slang, emojis, capitalization (e.g., "AMAZING" vs. "amazing"), and abbreviations that are common in political tweets.
The main benefit of lexicon-based methods is their simplicity and speed. They don’t require labeled training data or complex setups, which is often a priority for Twitter data in academic research, making them ideal for quick insights during live events using a Twitter analytics API. However, they often fail to grasp context, such as sarcasm or irony. For instance, a tweet like "Great job destroying healthcare" might score as positive due to the word "great", despite its negative tone. Another limitation is that most lexicons are focused on English, which can be a challenge in multilingual elections where tweets often mix languages.
Machine Learning Models for Sentiment Analysis
Machine learning approaches take sentiment analysis a step further by learning directly from data. These methods frame sentiment analysis as a classification problem, where algorithms are trained on labeled datasets - tweets tagged as positive, negative, or neutral. Popular models include Naive Bayes, Support Vector Machines (SVM), and Random Forest.
For political campaigns, Random Forest is particularly effective. In March 2026, software engineer Ameer Ali developed a political sentiment classifier using Random Forest, trained on thousands of labeled political snippets. The model achieved an impressive 84% accuracy across six categories: positive, negative, neutral, opinionated, substantiated, and sarcastic.
Ali explained, "Random Forest shone because it handles messy text well, ensemble trees voting on sarcasm via n-gram features".
This model uncovered a 45% rise in sarcasm after specific debate clips, offering valuable insights for campaign strategists.
To use machine learning effectively, tweets are converted into numerical representations (e.g., TF-IDF or Bag-of-Words). Advanced models like Bi-LSTM (Bi-Directional Long Short-Term Memory) and BERT (Bidirectional Encoder Representations from Transformers) can capture complex linguistic patterns. For example, a hybrid Bi-LSTM and Logistic Regression model achieved 82.32% accuracy on the Sentiment140 dataset, which includes 1.6 million labeled tweets.
The downside? Machine learning requires large amounts of labeled data and significant computational power. Models also need regular updates - every three months or so - to keep up with evolving political language. Additionally, these models often function as "black boxes", making it hard to explain why a specific tweet received a certain classification.
| Feature | Lexicon-Based | Machine Learning | Hybrid |
|---|---|---|---|
| Requirement | Predefined dictionary | Large labeled dataset | Both dictionary and labeled data |
| Complexity | Low | High | Very High |
| Accuracy | Lower (context issues) | Higher (data-driven) | Highest (combines strengths) |
| Interpretability | High (clear scores) | Low (opaque models) | Moderate |
| Best Use Case | Quick insights | Large-scale analysis | High-precision needs |
Hybrid Methods
Hybrid approaches combine the simplicity of lexicons with the learning capabilities of machine learning. For example, VADER can analyze slang and emojis, while its sentiment scores are then fed into a neural network to capture deeper linguistic patterns.
This combination often delivers the highest accuracy. A study in Scientific Reports highlighted:
"The inclusion of LR [Logistic Regression] improves interpretability while maintaining computational efficiency, ensuring a balance between accuracy and resource consumption".
In practice, a deep learning model like Bi-LSTM can extract contextual features, while Logistic Regression handles the final sentiment classification.
Hybrid models excel at detecting sarcasm in political tweets. Fine-tuning BERT models, for example, can boost sarcasm detection by 15% compared to standard neural networks. However, these systems require both labeled data and predefined lexicons, along with significant computational resources. They are best suited for campaigns that demand precision and have the technical infrastructure to support them.
Using Sentiment Analysis in Elections
This section explores how political campaigns turn Twitter sentiment data into actionable strategies. By analyzing voter sentiments, campaigns can identify key concerns, allocate resources wisely, and adjust messaging on the fly to improve their chances on Election Day.
Grouping Sentiments by Region or Demographics
Breaking down sentiment data by location can reveal where a candidate is performing well and where they might need to focus more attention. For instance, in November 2020, data scientist Pritam Guha used Python to map state codes and names, grouping tweets from all 50 states. By comparing the margins between positive and negative tweets for Donald Trump and Joe Biden, the analysis categorized states into groups like "Strongly Republican" or "Strongly Democratic", highlighting potential swing regions.
"In the political field, [sentiment analysis] is used to keep track of regions where the candidate is favorable and work towards regions where the candidate is not favorable in order to improve their chances in an election."
– Pritam Guha, Data Scientist
Since many tweets lack geolocation data, campaigns often combine signals like GPS coordinates, user-provided profile locations, and state abbreviations (e.g., "CA" for California) to improve accuracy.
Beyond geography, campaigns can link sentiment analysis with issue-specific topics like healthcare, immigration, or the economy. This allows them to identify which issues are generating positive or negative reactions.
In states with large populations, such as California, Texas, and Florida, the sheer volume of tweets can skew national sentiment averages. To counter this, campaigns use distribution models and analyze metrics like median and standard deviation, ensuring that sentiment scores reflect broader trends rather than being distorted by outliers.
These localized insights form a foundation for predictive analytics and help campaigns make real-time adjustments.
Predicting Election Outcomes
Sentiment analysis also plays a role in forecasting election results. A systematic review found that 78% of studies successfully predicted real-world election outcomes using Twitter sentiment data. For example, in a 2020 study at California State University, Sacramento, researcher Aleksey analyzed tweets featuring #JoeBiden and #DonaldTrump. By filtering data by state, calculating rolling sentiment means, and incorporating standard deviation into a linear model, the study accurately predicted battleground state outcomes in Arizona, Georgia, and Pennsylvania. The predictions achieved a Mean Squared Error of 3.8 for Biden and 3.6 for Trump, improving to 3.69 when additional metrics were included.
| Sentiment Category | Voter Perception | Campaign Action |
|---|---|---|
| Positive | Support for policies or candidate personality | Reinforce messaging in those regions |
| Negative | Frustration or disagreement with the platform | Address concerns or adjust strategy |
| Neutral | Lack of strong opinion or informational content | Increase engagement to shift sentiment |
These predictions provide campaigns with data-driven insights to refine their strategies further, particularly when paired with real-time monitoring.
Monitoring Real-Time Sentiment Trends
Tracking sentiment trends in real time allows campaigns to respond quickly to changes. Sudden spikes in negative mentions, for example, can signal a PR crisis or backlash to a policy announcement [3,4].
"By implementing a sentiment analysis model that analyzes incoming mentions in real time, you can automatically be alerted about sudden spikes of negative mentions."
– Federico Pascual, Hugging Face
Automated alerts for negativity spikes enable campaigns to act swiftly. Real-time monitoring also helps measure voter intensity by distinguishing neutral mentions from strong emotional reactions. A 2020 election study revealed that Donald Trump generated more intense positive and negative sentiments, while Joe Biden received a higher share of neutral mentions. Using rolling sentiment averages to track shifts after debates or major events allows campaigns to adjust their messaging almost immediately.
Challenges and Best Practices
Accurate sentiment insights are vital for election campaigns, but challenges like noise, bias, and scale can complicate the process. Twitter sentiment analysis, in particular, faces unique obstacles that can distort results. By recognizing these issues and employing effective strategies, campaigns can navigate the complexities of social media data to extract meaningful insights.
Common Challenges in Sentiment Analysis
Twitter data is inherently messy. Tweets often include abbreviations, emojis, hashtags, URLs, and HTML tags, all of which require thorough cleaning to ensure accuracy. Political discussions add another layer of difficulty, with sarcasm, irony, and subtle contextual cues often confusing models that rely on simple word-to-sentiment mappings.
Geographic bias is another challenge. States with larger populations generate more tweets, skewing the data. On top of that, user-provided location information is frequently inaccurate. Data scientist Pritam Guha highlighted this issue during his analysis of the 2020 election:
"The distribution of the data is poor... this may have included some bias in my analysis. Ideally, we should have same number of tweets for all states for both candidates."
Timing also matters. Sentiment can shift dramatically over the course of a campaign, and combining data from different periods - like before a debate versus after a scandal - can lead to misleading conclusions. Additionally, many sentiment models prioritize English, ignoring the multilingual or code-mixed content that reflects the diversity of many electorates.
Addressing these challenges requires a combination of focused cleaning methods, advanced tools, and tailored approaches to ensure reliable results.
Best Practices for Accurate Sentiment Analysis
Start by cleaning your data with precision. Use regex to remove irrelevant elements like HTML tags or URLs, but instead of discarding emojis, translate them into descriptive words using tools like emoji.demojize to retain their emotional meaning.
Leverage tools designed for social media language. For example, VADER (Valence Aware Dictionary and sEntiment Reasoner) is specifically built for informal text. For political content, explore fine-tuned models like ElecBERT, which understands election-specific language. Always cross-check your model's predictions against historical election outcomes. Research shows that about 78% of machine learning analyses on Twitter data have accurately predicted election results, though there’s still a 22% margin for error.
To reduce geographic bias, use distribution models and median values to balance data from states with varying tweet volumes. For multilingual content, either filter tweets by language or use models trained to handle multiple languages to avoid missing key voter groups.
Scaling Your Sentiment Analysis
Once you've refined your analysis with these best practices, scaling up requires reliable infrastructure to handle large volumes of data. Monitoring millions of tweets during an election can quickly exceed the limits of standard developer APIs, which typically restrict researchers to around 3,200 recent tweets per handle.
Platforms like TwitterAPI.io offer solutions to these scaling challenges. With pay-per-request pricing at $0.00015 per tweet, faster response times of around 800ms, and the ability to handle over 1,000 queries per second, it’s a powerful tool for large-scale analysis. It also provides access to extensive historical archives and a quick setup process, allowing campaigns to immediately collect data during critical moments like debates or breaking news events.
Conclusion
Twitter sentiment analysis has become a critical tool for modern election campaigns. With its 300 million active users and bite-sized 280-character posts, Twitter offers a prime space for tracking voter opinions in real-time. As experts point out, the battle for voter influence increasingly plays out on social media. Overlooking sentiment trends on these platforms risks missing key shifts in voter behavior. This underscores the importance of leveraging real-time social sentiment to shape campaign strategies and, ultimately, election outcomes.
Key Takeaways
Start with clean, precise data collection. Remove retweets, user mentions, and URLs to ensure sentiment scores reflect genuine voter opinions. The choice of analysis method depends on your resources. Tools like VADER are great for quick insights, while machine learning models such as BERT provide a deeper, more contextual understanding.
Incorporating location and demographic data can also sharpen campaign strategies. By analyzing regional sentiment patterns, campaigns can identify strongholds and pinpoint areas needing more attention to boost electoral performance. Research shows that around 78% of machine learning applications using Twitter data have accurately predicted election results.
For large-scale sentiment tracking, tools like TwitterAPI.io offer practical, cost-efficient solutions. With its pay-per-request pricing and ability to handle high tweet volumes, this tool is ideal for monitoring millions of tweets during pivotal moments like debates or breaking news. Such scalable infrastructure ensures campaigns can stay on top of voter sentiment when it matters most.
Future of Sentiment Analysis in Elections
Looking ahead, election analytics is set to grow even more advanced. The shift from lexicon-based methods to transformer models like ElecBERT is already enhancing the ability to interpret complex political language. Explainable AI (XAI) is also gaining traction, offering greater transparency for campaign strategists and policymakers. Additionally, multilingual sentiment analysis is expanding, enabling campaigns to better understand diverse electorates that use code-mixed or non-English content.
However, a significant challenge remains. Researcher Onkar Abhishek Tiwari highlighted this limitation:
Twitter alone can't be a dependent tool for predicting election outcome. Twitter data alone cannot capture the Silent Majority.
Future advancements will need to address this gap by accounting for the "dark matter" of social sentiment - those who consume content but rarely post. Campaigns that integrate Twitter analysis with other data sources and consider broader global contexts will gain a more accurate and comprehensive view of voter sentiment as they move forward.
FAQs
How accurate is Twitter sentiment for predicting U.S. election results?
Twitter sentiment analysis has demonstrated a noticeable connection to U.S. election results. For instance, research during the 2016 election revealed as much as a 94% correlation with polling data. That said, while these findings are intriguing, the method isn't entirely dependable for making precise predictions. Election outcomes are influenced by a wide range of factors that extend well beyond the scope of social media sentiment.
How can I reduce bias from bots and uneven tweet volume across states?
To make sentiment analysis for election campaigns more accurate, it's important to address bias by using bot detection techniques and normalizing data based on geographic activity.
Start by identifying bots. Look for abnormal patterns, such as unusually high activity, inflated follower counts, or suspicious engagement rates. These signs often indicate automated accounts that could skew the data.
Next, normalize tweet data by comparing it to population sizes or typical activity levels in each state. This helps balance the data and ensures that states with higher activity don’t disproportionately influence the results.
By combining bot detection and geographic normalization, you can create a more reliable foundation for analyzing public sentiment during election campaigns.
When should I use VADER vs BERT for election tweets?
VADER is perfect for fast, rule-based sentiment analysis of short tweets, especially when monitoring elections in real time. It focuses on speed and ease of interpretation. On the other hand, BERT-based models, like Twitter-roBERTa, are better at handling subtle, context-dependent sentiments. These models shine when analyzing tweets with sarcasm, idioms, or more intricate language. If you need a deeper understanding of sentiment, go with BERT. But for large-scale, straightforward sentiment scoring, VADER is the better choice.
Tags
Related articles
Ready to get started?
Try TwitterAPI.io for free and access powerful Twitter data APIs.
Get Started Free